服务热线:010-66095089/13521200337(微信)


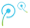

全国智慧农业“种子工程”案例征集活动号角吹响,2020我们一起出发!

【申报】AIOT ✖ 大农业生态峰会暨智慧农业“种子工程”案例征集

首届物联网与人工智能技术应用案例征集\/中国物联网与人工智能技术应用大会

关于征集发布前沿领域科技成果相关事宜


当今物理和天文实验所产生的海量信息,没有任何一个人或者团队可以完整的处理。
有些实验数据每天以千兆字节的规模在增加——而且这个趋势只会越来越明显。
想象一下,一台以平方公里为单位阵列的射电望远镜,预计将于2020年中开始进行科学观测,每年将产生的信息数量可与整个互联网相匹敌。
面对如此信息洪流,许多科学家不得不求助于人工智能。
这是一个研究者眼中神奇的工具。
只需少许人工输入,包括人工神经网络(计算机模拟人脑神经网络)在内的人工智能系统就可以轻松处理成千上百万条信息,并发现其中的异常和人类绝难识别的模式。
利用计算机协助科学研究的历史可以被追溯到75年前。
早在几千年前,人类就已经开始从数据中寻找有效信息。科学家认为机器学习和人工智能所运用的前沿技术,是一种研究科学的全新方法。
这种方法,即生成模型(generative modeling),仅基于数据就可以找到与观测数据相关的诸多解释中最为合理的理论。更重要的是,这一过程无需预先编程,对于系统可能产生作用。生成模型的支持者觉得它的创新程度可以被认为是了解宇宙的潜在的“第三种方法”。
通常,我们通过观察来知晓万物。约翰尼斯·开普勒就是通过研究第谷·布拉赫的星象图来试图找到天体运动的规律(所有行星都是椭圆轨道上运行的),建模同时也推动着科学进步。天文学家模拟银河与其邻近星系仙女座的移动轨迹后,预测两星系将于几百万年之后相撞。观察和建模都能帮助科学家建立假设,而用进一步的观察来检验假设。相较之下,生成模型区别于以上两种方法。
“这是第三种方法,介乎于观察和建模之间。”天文学家Kevin Schawinski介绍说。他此前一直就职于苏黎世联邦工业大学(ETH Zurich),同时也是当今生成模型最狂热的支持者之一。“它提供了一种解决问题的新方法。”
有些科学家将生成模型和其他新技术简单地归类为研究传统科学的工具。但绝大部分人的共识则是人工智能能够带来巨大的影响,而且在科学研究领域的作用也将越发显着。费米实验室的天体物理学家Brian Nord以用人工神经网络研究宇宙而闻名。
他担心人类科学家所做的一切都可以被自动化,而持有这种观点不在少数。Nord说,“这种想法让我感到恐慌”。
神奇的GAN,基于生成的探索
还在读书的时候,Schawinski已经在数据驱动科学领域已经小有名气。博士学位期间,他的课题是基于表象对数千个星系进行分类。由于当时还没有可以用来解决问题的软件,Schawinski就想到了采用群众外包的方式——因此大众科学星系园项目也就应运而生。
自2007年起,天文学家开始用电脑录入关于星系分类的最佳猜测,在多数决定原则下通常被证明为是正确的分类。之后这一项目取得了成功,但Schawinski却意识到人工智能已经可以取而代之。“在今天,一个有天赋、有机器学习背景且懂得云计算的科学家能够在一个下午完成所有的工作。”
Schawinski在2016年开始使用生成模型这种新工具。本质上,生成模型在确定条件X的前提下有多少概率能够得到结果Y。这个方法已被证明极为有效且运用广泛。例如,你用生成模型处理一组人脸照片,每张照片都标记了主人公的年纪。电脑程序在梳理这些“训练数据”时,会有意识地将较老的面容和逐渐增加的皱纹数量关联在一起。
最终,它就有能力“识别”人脸所对应的年纪——原理是它能够预测任何年龄段人脸所可能产生的变化。

以上的人脸都是生成的。上图第一行(A)和左边第一列(B)是由生成对抗网络(GAN)借助真人人脸构建模块构成的。GAN随后将A中人脸的基本特(如年龄和脸型)与B中细致特征(如发色和眼球颜色)相结合,生成了上图中其他的人脸。
生成模型系统中最有名的就是生成对抗网络(GAN)。在充分接触训练数据后,一个生成对抗网络能够修复像素损坏或确实的图像,或是锐化那些模糊的照片。生成对抗网络通过对比的方法(即对应着术语“博弈”)来推断出缺失信息:该网络的组成部分之一生成器负责生成假数据,而另外的组成部分鉴别器则负责在数据中区分出这些假数据。随着程序的运行,两个组成部分的表现也得到了显着提升。尤其是在由生成对抗网络最新提供的超现实人脸中,如同上图标题中所示,有一些让你感觉“不存在于我们的世界却又真实地吓人”。
更宽泛的说法,生成模型吸收数据(通常为图像,但也不完全是)并拆分成一组基本但抽象的构建模块——科学家将其成为数据的“隐空间”。该算法操控隐空间的元素来探究其如何影响源数据,而这也能帮助发现系统中正在运行的物理变化。
隐空间的概念很抽象且难以用视觉表现,但假设用一个粗略的比方,想一想当你在判断人脸对应的性别时你的大脑究竟在如何运转。你可能会关注到发型、鼻子形状等,以及难以用言语表达的其他特征。电脑程序也在相似地寻找数据中地显着特征:虽然它不会知道什么是胡子或性别,但如果学习的训练数据中有标记着“男性”、“女性”或“长着胡子”的照片时,电脑程序将会很快地推断出两者之间的相关性。
12月发表在《Astronomy & Astrophysics》期刊的一篇论文中,Schawinski和他在苏黎世联邦工业大学的同事Dennis Turp和Ce Zhang使用生成模型来研究星系演化过程中的物理变化。(他们所用的软件与生成对抗网络相似,但其在对隐空间处理的技术与生成对抗网络有所差异,所以从技术角度来说并不属于生成对抗网络)他们的模型创建了人工数据集,用于测试物理变化的假设。比如说,他们想知道恒星形成的“淬火”——形成速率中的快速减弱——与星系环境密度的关联性。
对Schawinski而言,关键问题是仅凭数据本身能够挖掘多少和恒星与星系演变相关的信息。“让我们忘记所有关于天体物理学的知识。”他说,“仅仅使用数据本身,我们又能在多大程度上重新认识这些知识?”
首先,星系的图片被压缩到它们的隐空间。Schawinski随即微调空间中的某一个元素,使其能对应上该星系的特定环境变化——比如,周边物质的密度。接着,他就可以重新生成一个星系来观察不同之处。“所以现在我就拥有了一台假设生成设备。用它可以使我手上所有原本都是处于低密度环境的星系看上去都像是在高密度环境中一样。”
Schawinski他们发现当星系改变所处环境从低密度变成高密度时,星系的颜色变得更红,星系中的恒星也变得更加向中部集中。Schawinski指出这些观察结果与现存的星系观测相吻合,但问题是为什么会这样。
Schawinski说后续分析步骤还没有实现自动化,“我必须以人类的身份参与其中,那么试想‘究竟是怎么样的物理原理可以来解释这种效应?’”对这个问题有两种解释:星系在高密度环境中变得更红可能是因为高密度环境中充斥着很多尘埃,亦或是因为恒星的形成变少了。(换句话说,星系中的恒星变得更老了)现在,有了生成模型就可以检验这两种思路。改变隐空间中与尘埃和恒星形成速率相关的元素来探究它们如何影响星系的颜色。“答案是显然的。”Schawinski说,“星系变红是恒星形成变慢,而并不是受尘埃的影响。因此,我们应该采纳这种解释。”

利用生成概率模型,天体物理学家可以研究宇宙星系从低密度区到高密度区过程的变化,以及导致这些变化的物理过程,这是一种与传统模拟方法相依相异的方法。Schawinski教授指出,假设驱动是模拟的本质,研究中涉及的基本物理定律决定了系统所显示得结果。在所有物理假设成立的基础上,我们将一个行星结构和一个暗物质行为导入系统,模拟其过程并运行,结果在一定程度上与现实相反,但事实上,我们并不知道真实情况及需要的假设条件,我们寄希望于数据本身所产生的结果。
模拟的成功并不能取代天文学家和研究学者的地位,但这意味着在天体物理学域,对象和过程的学习程度的发生转变:我们通过生成概率模型,从庞大的数据库获取信息变得唾手可得。Schawinski教授指出,虽然这不是完全自动化的科学,但表明我们有能力在一定程度上构建自动化科学过程的工具。
生成概率模型显然是强大的,但它是否真正代表了一种新的科学方法呢?
供职于纽约大学及Flatiron研究所(与Quanta一样都由Simons基金会资助)的宇宙学家David Hogg教授指出,这项技术虽然令人叫绝,但归根结底来说,只是一种从数据中提取规律的复杂方法。几个世纪以来,天文学家一直在使用这种先进的方法进行数据观察和分析。
Hogg教授和Schawinski教授的工作都对AI十分依赖,Hogg教授使用神经网络方法,根据光谱对恒星进行分类,并使用数据驱动模型推断恒星的其他物理属性。他认为他和Schawinski教授的工作都是经过实践检验的科学,并且不认为这是第三种科学方式。他们致力于打造一个成熟运用数据的团体,尤其是在数据比较方面,即使现在Hogg教授的工作仍有待观察。
任劳任怨的AI助理
无论在概念上是否具有新颖性,很明显AI和神经网络已经在当代天文学和物理学研究中扮演了重要角色。
在海德堡理论研究所,物理学家Kai Polsterer教授的天文信息学小组,致力于研发以数据为中心的天体物理学研究方法。最近,他们一直在使用机器学习算法从星系数据集中提取红移信息,这在以前是一项艰巨的任务。
Polsterer教授将这种基于AI的系统称作“任劳任怨的助理”,该系统可以连续梳理数据数小时,不厌倦不抱怨,完成所有繁琐乏味的工作,这让研究人员有时间和精力做一些他们擅长的有趣的科学研究。
Polsterer教授指出系统并不是完美无缺,算法只能执行训练过的事项,对于未知输入无法响应。例如,如果输入一个已知星系,系统可以估计它的红移信息和年龄,但如果输入一张自拍照或腐烂的鱼的图片,系统也会输出一个极端错误的估计年龄。在此案例中人类科学家扮演者重要角色,由此他认为此项技术最终需要研究人员负责监控及解释。
供职于费米实验室Nord教授指出重要的一点:神经网络方法不仅要提供计算结果,而且要提供误差区间——这是每个大学生统计课上都学过的。在科学领域,如果只计算而不提供相关误差估计,那么结果并不值得信任。
和其他AI研究员一样,Nord教授也担心神经网络系统结果的“不易解释”这一缺陷,通常系统提供的仅是结果,而不显示具体这些结果是如何得到的。
然而并不是所有人都认为这是一个问题。法国CEA Saclay理论物理研究所的研究员Lenka Zdeborová指出,人类的直觉也是如此“不易解释”。比如你看一张照片后立即认出是一只猫,但事实上你不知道这是怎么回事,从某种意义上说,大脑就是一个黑盒子。
不仅是天体物理学家和宇宙学家向AI推动的数据驱动、数据推动科学迁移,量子物理学家也使用神经网络来解决一些十分棘手且重要的问题。
供职于周界理论物理研究所和安大略省滑铁卢大学的Roger Melkoof教授,使用神经网络技术解决了描述多粒子系统的数学波函数问题。Melkoof教授将必不可少的AI技术称为“维数的指数诅咒”,波函数形式的可能随粒子数量呈指数增长。这一模拟过程的难点类似尝试在象棋或围棋游戏中找出最佳走法,即你在试图走下一步前,会想象你的对手会如何应对,在这些走法中选择最佳的一个,但每走一步,可能性就会呈指数激增。
当然,AI系统已经掌握了国际象棋和围棋游戏的玩法,从十年前征服国际象棋,到2016年AlphaGo击败了人类顶级围棋棋手。Melkoof教授由此认为,人工智能在量子物理学中同样具有适用性。
科学研究的“第三种方法”
无论Schawinski教授认为AI是科学研究的“第三种方法”是否正确,或者如Hogg教授认为,这种方法只是传统观察和数据分析的“外挂”,但毫无疑问的是AI正在改变科学发现方法,并起到明显的促进作用,那么AI革命将在科学研究上走多远?
有人对“机器人科学家”的成就夸夸其谈。十年前,一位名叫亚当的AI机器人化学家研究了面包酵母的基因组,并找出了制造特定氨基酸的基因。亚当通过观察某些基因缺失的酵母株,将结果与具有这些基因菌株的行为进行比较。
最近,格拉斯哥大学的化学家Lee Cronin教授一直在使用机器人随机混合化学物,看看会形成什么样的新化合物。该系统通过质谱仪、核磁共振仪和红外光谱仪实时监测反应并最终预测哪种组合反应最为强烈。Cronin教授指出,即使这个机器人系统不能带来进一步的发现,它也能使化学家们的研究速度提高约90%。
苏黎世联邦理工学院的另一组科学家去年利用神经网络,从一组数据中推导出了相关物理定律。他们的系统类似于机器人开普勒(kepler),通过记录从地球上看到太阳和火星在天空中的位置,重新发现了太阳系的日心模型,并通过观察碰撞的球体,得出了动量守恒定律。由于物理定律通常不止一种表达式,研究人员想知道这个系统是否会提供新的方法表达已知物理定律。
以上都是AI启动科学发现过程的案例,尽管在每种情况下,我们都可以讨论这种新方法的革命性。但最有争议且紧急的问题是,在这个数据堆积如山的时代,我们能从中收集多少信息。
在《The Book of Why》(2018)一书中,计算机科学家Judea Pearl和科学作家Dana Mackenzie指出,数据其实并不是十分智能,数据无法解释因果关系,使用各个模型分析数据的论文或研究都只给出结果或变换数据,不能做出解释。Schawinski教授同意Pearl教授的观点,但是指出这种观念偷换了概念,他从未声称要以这种方式推断因果关系,而只是使用这种方法可以比常规方法做的更多。
科学需要创造力,但到目前为止,没有恰当的方法将创造力引入机器编程。Polsterer教授说“提出一个有逻辑的新理论需要创造力。而每当你需要创造力的时候,你就需要人类。”创造力从何而来?Polsterer教授觉得创造力和“无聊”有关,机器是无法感受到无聊的。“想变得有创造性,你必须讨厌无聊。我不认为机器会觉得无聊。”但另一方面,我们却用着“创意”和“灵感”等词汇来描述深蓝(Deep Blue)和AlphaGo等程序。描述机器“思想”内部发生了什么的困难反映了我们探索自己的思维过程是多么的困难。
Schawinski教授最近离开学术界进入了私企,运营一家名为Modulos的初创公司,Modulos雇佣了许多ETH的科学家,公司在官网口号是,“在AI和机器学习的发展风暴中心工作”。无论当前的AI技术和成熟技术间存在何种障碍,他和其他专家都认为,机器人已经准备好做越来越多的人类科学家的工作,即使机器在这方面存在一定限制性。
在可预见的未来,我们能否制造出一台使用生物硬件的机器,能够解决那些连世界上最聪明的人类也无法独立完成的物理或数学问题。科学的未来最终是否有可能归宿于机器驱动,令人期待。
上一篇:5G+医疗:医疗发展新方向

