服务热线:010-66095089/13521200337(微信)



全国智慧农业“种子工程”案例征集活动号角吹响,2020我们一起出发!

【申报】AIOT ✖ 大农业生态峰会暨智慧农业“种子工程”案例征集

首届物联网与人工智能技术应用案例征集\/中国物联网与人工智能技术应用大会

关于征集发布前沿领域科技成果相关事宜


图源:pixabay
原文来源:arXiv
原文链接:https://arxiv.org/pdf/1803.10122.pdf
作者:David Ha、Jurgen Schmidhuber
「雷克世界」编译:嗯~是阿童木呀、KABUDA
我们探索构建通用强化学习环境中的生成式神经网络模型。我们的世界模型(world model)可以以一种无监督的方式进行快速训练,以学习环境的压缩时空表征。通过使用从世界模型中提取的特征作为智能体的输入,我们可以对一个非常简洁且简单的策略进行训练,以解决所需的任务。我们甚至可以在一个完全由智能体本身的世界模型所生成的梦幻梦境中对智能体进行训练,并将此策略迁移回实际环境中。

世界模型,来自Scott McCloud的认识漫画
人类根据他们使用有限的感官对世界的感知,开发出一个有关世界的心智模型。而我们所做的决策和行动都是基于这种内部模型的。系统动力学之父——Jay Wright Forrester将心智模型定义为:
我们脑海中所承载的有关周围世界的图像,只是一个模型。世界上没有一个人能够在其脑海中对全部的世界、政府或国家进行透彻的想象。他只是选择了概念,以及它们之间的关系,并用它们来表示真实的系统。(Forrester于1971年提出)
为了处理流经我们日常生活中的大量信息,我们的大脑学习对这些信息进行时空方面的抽象表征。我们能够观察一个场景,并记住有关它的一个抽象描述(Cheang和Tsao于2017年、Quiroga等人于2005年提出)。还有证据表明,我们在任何特定时刻所感知的事物,都是由我们的大脑基于内部模型对未来做出的预测所掌控的(Nortmann等人于2015年、Gerrit等人于2013年提出)。
理解我们大脑中的预测模型的一种方法是,它可能不是仅仅预测未来的一般情况,而是根据当前的运动动作预测未来的感官数据(Keller等人于2012年、Leinweber等人于2017年提出)。当我们面临危险时,我们能够本能地依据这个预测模型采取相应的行动,并执行快速的反射行为(Mobbs等人于2015年提出),而无需有意识地规划出行动计划。

我们所看到的事物是基于我们大脑对未来进行的预测(Kitaoka于2002年、Watanabe等人于2018年提出)
以棒球为例。一个击球手只有几毫秒的时间来决定该如何挥棒击球,让这要比视觉信号到达我们的大脑所需的时间短得多。他们之所以能够打出每小时115英里的快速球,是因为我们有能力本能地预测出球将何时何地走向何方。对于职业球员来说,这一切都是在潜意识中发生的。他们的肌肉在适当的时间和地点按照他们的内部模型的预测反射性地挥棒击球(Gerrit 等人于2013年提出)。他们可以迅速根据自身对未来的预测采取行动,而无需有意识地将可能的未来场景铺展开以进行规划(Hirshon于2013年提出)。
在许多强化学习(RL)(Kaelbling等人于1996年、Sutton和Barto于1998年、Wiering和van Otterlo于2012年提出)问题中,人工智能体也受益于具有良好的对过去和现在状态的表征,以及良好的对未来的预测模型(Werbos等人于1987年、Silver于2017年提出),最好是在通用计算机上实现的强大的预测模型,如循环神经网络(RNN)(Schmidhuber于1990、 1991年提出)。
大型RNN是具有高度表达性的模型,可以学习数据的丰富的时空表征。然而,在以往的研究中,许多无模型强化学习方法通常只使用参数很少的小型神经网络。强化学习算法常常具有信用分配问题(credit assignment problem)的局限性,这使得传统的强化学习算法难以学习大型模型的数百万个权重,因此,在实践中往往使用较小的网络,因为它们在训练期间能够更快地迭代形成一个良好的策略。

在这项研究中,我们构建了OpenAI Gym环境的概率生成模型。使用从实际游戏环境中收集的记录观测值对基于RNN的世界模型进行训练。对世界模型进行训练之后,我们可以使用它们来模拟完整的环境并训练对智能体进行训练
理想情况下,我们希望能够有效地对基于RNN的大型智能体进行训练。反向传播算法(Linnainmaa于1970年、Kelley于1960年、Werbos于1982年提出)可以用来对大型神经网络进行有效的训练。在这项研究中,我们通过将智能体分为一个大的世界模型和一个小的控制器模型,从而对大型神经网络进行训练以解决强化学习任务。首先,我们对大型神经网络进行训练,以无监督的方式学习智能体的世界模型,然后训练较小的控制器模型,学习使用这个世界模型执行任务。一个小型控制器让训练算法专注于小型搜索空间上的信用分配问题,同时不会以大的世界模型的容量和表现力为代价。通过智能体世界模型的视角对智能体进行训练,我们表明,它可以学习一个高度紧凑的策略以执行其任务。
虽然有大量关于基于模型的强化学习的研究,但本文并不是对该领域当前状态的评述(Arulkumaran等人于2017年、Schmidhuber于2015年提出)。相反,本文的目标是从1990—2015年关于基于RNN的世界模型和控制器组合的一系列论文中提炼若干个关键概念(Schmidhuber于1990年、1991年、1990年、2015年提出)。
我们证明了在模拟潜在空间梦境中训练智能体执行任务的可能性。这一方法拥有许多切实优点。例如,在运行计算密集型游戏引擎时,需要使用大量的计算资源来将游戏状态渲染到图像帧中,或计算与游戏不直接相关的物理量。相信我们都不情愿在现实环境中浪费训练智能体的周期,而是更乐意在模拟环境中尽可能多地训练智能体。此外,在现实世界中训练智能体的代价甚至更大,因此,渐进式地进行训练以模拟现实的世界模型可以更容易地尝试使用不同方法来训练我们的智能体。
此外,我们可以利用深度学习框架,在分布式环境中使用GPU,从而加速世界模型的模拟。将世界模型作为一个完全可微的循环计算图的好处在于,我们可以直接在梦境中使用反向传播算法对其策略进行微调,从而实现目标函数最大化(Schmidhuber于上世纪90年代提出)。
对视觉模型V使用VAE并将其作为独立模型进行训练也存在局限性,因为它可能会对与任务无关的部分观测进行编码。毕竟,根据定义来看,无监督学习不知道哪些是对当前任务有用的。例如,在Doom环境中,它在侧墙上复制了不重要的详细砖瓦图案,但在赛车环境中,它没有在道路上复制与任务相关的砖瓦图案。通过与预测奖励的M模型一起训练,VAE可以学习专注于图像中与任务相关的领域,但这里需要权衡的一点是,如果不进行重复训练,那么我们或许就不能有效地利用VAE再次执行新任务。
学习任务的相关特性也与神经科学有所关联。当受到奖励时,基本感觉神经元便会从抑制中释放出来,这意味着它们通常仅学习与任务相关的特征,而非任何特征,至少自在成年期是这样的(Pi等人于2013年提出)。
今后的工作可能会探讨如何使用无监督分割层(Byravan等人于2017年提出)来提取更好的特征表征,这与所学习的VAE表征相比具有更好的实用性和可解释性。
另一个令人关切的问题是,我们世界模型的容量有限。尽管现代存储设备可以存储使用迭代训练过程生成的大量历史数据,但我们基于长短期记忆网络(LSTM)(Hochreiter和Schmidhuber于1997年提出;Gers等人于2000年提出)的世界模型可能无法在其权重连接中存储所有记录的信息。虽然人类的大脑可以保存几十年甚至几个世纪的记忆(Bartol等人于2015年提出),但我们通过反向传播训练的神经网络容量有限,并受灾难性遗忘等问题的影响(Ratcliver 于1990年,French于1994年,Kirkpatrick等人于2016年提出)。如果我们希望智能体学会探索更复杂的世界,那么今后可以探索用更高容量的模型取代小型MDNRNN网络(Shazeer等人于2017年,Ha等人于2016年,Suarez等人于2017年,van den Oord等人于2016年,Vaswani等人于2017年提出),或加入外部记忆模块(Gemici等人于2017年提出)。
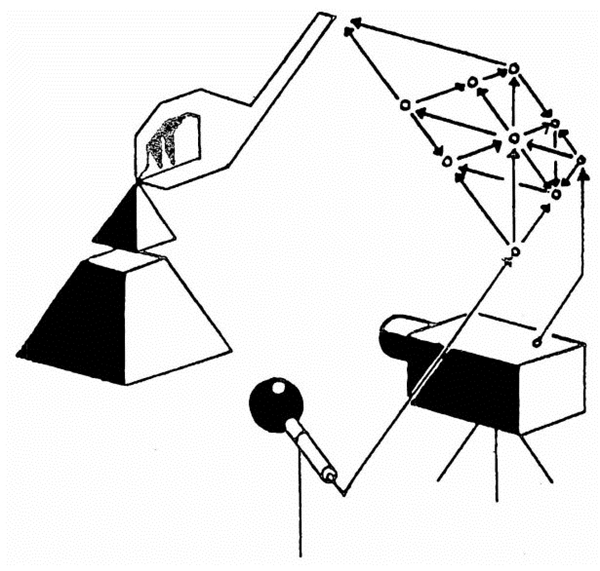
基于RNN的控制器与环境交互的古代绘图(Schmidhuber于1990年提出)
就像早期基于RNN的C-M系统一样(Schmidhuber等人于上世纪90年代提出),我们模拟了可能的未来时间步长,而没有从人类的层次化规划或抽象推理中获益,这往往忽略了不相关的时空细节。然而,更常见的“学会思考”(Schidhuber于2015年提出)方法并不局限于这种相当幼稚的方法。相反,它允许循环C学习循环M的子例程,并重用它们以任意的计算方式解决问题,例如,通过层次化规划或利用类似M的程序权重矩阵的其他部分。近期,One Big Net(Schmidhuber,2018年)扩展了C-M方法,它将C和M合并成一个网络,并使用类似Power Play的行为回放(Schmidhuber于2013,Srivastava等人于2012年提出)(其中教师网络(teacher net)的行为被压缩成学生网络(student net)(Schmidhuber于1992年提出)),以避免在学习新网络时忘记旧的预测和控制技能。这些具有更通用方法的实验在未来有待进一步研究。

