服务热线:010-66095089/13521200337(微信)



全国智慧农业“种子工程”案例征集活动号角吹响,2020我们一起出发!

【申报】AIOT ✖ 大农业生态峰会暨智慧农业“种子工程”案例征集

首届物联网与人工智能技术应用案例征集\/中国物联网与人工智能技术应用大会

关于征集发布前沿领域科技成果相关事宜


大数据文摘出品
编译:睡不着的iris、小七、云舟
潮鞋交易正成为一门潜力巨大的生意,而这门生意的关键,是识别真伪。
一家名为GOAT的潮鞋交易平台正尝试用机器学习,从七张照片中识别出一双鞋子是否是真的。

每双鞋的卖家会向平台发送七张标准照片:从鞋子的不同角度拍摄标准化照片,即鞋跟,鞋底和侧面,然后进行处理。
GOAT将基于这些图片使用机器学习验证它们是否真实,并将它们与真实和假冒版本的图像数据库进行比较。
一旦上市,买家就会对鞋子出价,类似于eBay。
这家主打小众市场的交易平台希望“为买家和卖家提供最大的、安全的潮鞋交换市场”,建立和完善认证流程,以打击在线运动鞋市场的欺诈行为。
成立3年以来,该应用程序目前已经拥有700万用户,囊括超过400,000个潮鞋品牌,包括Yeezy Boosts,Nike Air Max's和Chanel X Pharrell等。
“这是图像识别与机器学习的结合,因为我们每天都会在工作中获得如此多的相同类型的鞋子,”GOAT创始人表示。
大量的用户积累也让GOAT构建了一个真实潮鞋模型的数据库。这一高质量的“潮鞋图像”数据库成为了GOAT的巨大宝藏。

除了辨别真伪,GOAT数据团队的首要任务是给这些风格迥异的潮鞋归类,进而引导用户在这个app上展示自己独特的风格,引导潮鞋潮流。

这不是一项简单的任务。GOAT的产品目录中由超过30,000双的潮鞋(并且还在不断增长),它们都有独特的风格、轮廓、材质、颜色等,手动将整个产品目录归类是个棘手的问题。
另外每有鞋上新都可能改变谈论潮鞋的方式,这意味着GOAT需要对这一归类方式时有更新。
解决这个问题的一个方法是应用机器学习。为了跟上不断变化的潮鞋市场,GOAT使用可以找到对象之间的关系的模型,而无需明确指出我们要找的是什么。在实践中,这些模型像人一样去学习特征。
在本篇文章中,GOAT的一位机器学习工程师Emmanuel Fuentes
详细介绍了GOAT如何使用机器学习构建视觉属性作为通用潮鞋语言的基础。
隐变量模型
我们在GOAT使用人工神经网络近似估算产品目录中最明显的视觉特性,即隐变异因子(latent factors of variation)。机器学习中,这属于流形学习(manifold learning)的范畴。
流形学习是基于假设数据分布(例如潮鞋的图像)通常可以在局部欧式空间表示成较低纬特征,同时保留了大部分的有用信息。结果将成千上万的图像像素转换成可解释的具有细微差别的特征,并压缩成一些数字的列表。
流形是什么?
想象下你如何告诉你朋友去你家的路线。你永远不会用一系列原生GPS坐标来描述如何从他们家里到你家。在这个比喻里面中,GPS代表的是高纬度、宽域随机变量。相反,你可能会以一系列的街道名称和转向作为坐标的近似值指导他们驾驶,这就是我们的流形(manifold)。
建模
由于没有昂贵的基础真值标签,我们使用诸如变分自编码器(VAE)、生成对抗网络(GAN)以及各种混合的非监督学习模型来学习流形。模型将主要的潮鞋照片转换为审美的隐因子,这也被称为嵌入(embeddings)。
许多情况下,这些模型利用某种形式或形状的自动编码框架来推断隐空间(latent space)。模型的编码器将图像分解成隐向量,然后通过解码器重构图像。遵循这个步骤,我们会衡量模型重构输入和计算正确性的能力,称为损失。模型利用损失作为改进标准,不断迭代压缩和解压缩越来越多的图像。重构任务推动“领结长相”模型来学习对任务最有用的嵌入。与主成分分析(PCA)等其他降维技术类似,这项技术用来对数据集的变异性进行编码。
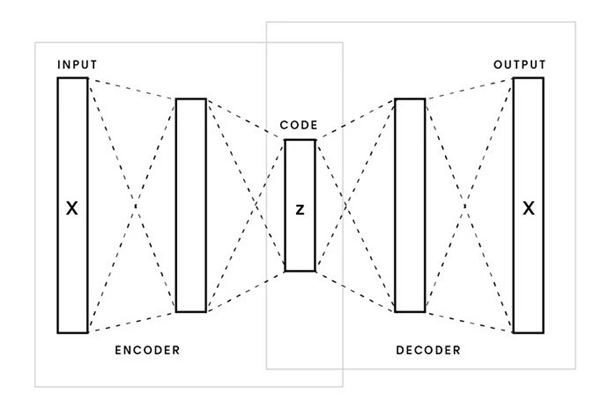 原型自动编码器
原型自动编码器
注意事项和设计选型
仅仅能重构图像通常是不够的。传统自动编码器可以将数据集转换成规整的查询表,但泛化能力较弱。这会导致学习得到的流形不佳,样本间呈现“裂缝”或“悬崖”状的空间。现代模型通过各种方式解决这个问题。
有些,例如着名的变分自编码模型(VAE),为损失函数增加一个散度归一化项,将隐空间约束至一些理论支持。更详细地说,这类模型大部分惩罚与某种高斯分布或均匀分布的先验分布不匹配的隐空间,并通过选取散度指标来估算误差。
在很多情况下,选取合适的模型取决于散度测量、重构误差函数和施加先验的设计选型。例如,β-VAE和Wasserstein自动编码模型分别利用KL散度(又称相对熵,Kullback-Leibler divergence)和对抗损失。通常需要在输出质量和多样性之间进行权衡,根据你学习的嵌入用例,你会更偏爱某一种设计选型。
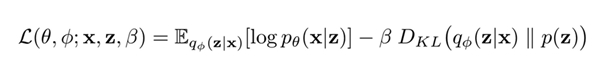
β-VAE损失函数、重构和权重散度项
当潮鞋的审美编码成我们视觉潮鞋语言,我们更希望得到一个健壮和多样化的隐因子空间,足以覆盖我们大部分的产品目录。换言之,我们希望模型可以最大范围地表示潮鞋,而非牺牲代价去表示JS Wings那样独特的款式。
“看起来像”案例
我们训练一个VAE去学习主要产品照片的隐空间。保持隐向量固定,我们直观看到模型如何一步步训练,构建复杂和抽象的层。

通过解码器生成照片,在逐步增加的训练迭代时,每张图像是一个固定的隐向量
该模型倾向于在每个维度创建更多独立的人类可解释因子,这称之为解纠缠(disentanglement)。首先,模型着重对比鞋底和鞋面差别来重新构建最合适的轮廓。然后,重构整个轮廓的灰色梯度,再开始学习基础颜色。在了解了轮廓类型之后,例如,靴子还是潮鞋,高帮还是低帮,网络开始处理复杂的设计款式和颜色,这些都是最终的差异性因素。
为了展示学习后的流形并检查学习曲面的“平滑度”,我们通过插值法进一步可视化。选择看似不同的潮鞋作为锚点(anchors),然后判断它们在隐空间中的过渡。每个隐向量的插值被解码成图像空间的视觉检验,并与整个目录里最接近的实际产品相匹配。动图说明了映射学习特征的概念。

锚定球鞋之间的插值
为了进一步探索隐空间,我们使用单双潮鞋,每次在每个方向修改一个隐因子,观察它是如何变化的。因子表示“中帮“或“靴子”的属性和鞋底颜色只是网络学习到的一小部分可感知的视觉特征。不同模型的隐因子数量和彼此间独立性各有差异。解纠缠的特性是我们研究的一个活跃领域,期望借此改善模型的嵌入。

隐因子探索,每行使用相同的锚定潮鞋,每列是重构的隐向量的修正值,先验是标准正太分布
此外,我们可以通过将隐含向量压缩成2D或3D图来查看整个产品目录的大趋势。我们使用诸如t-SNE这类工具来映射隐空间,可视化点抽样和大规模标注。

t-SNE隐空间探索
从逻辑上讲,如果每双潮鞋只是隐因子的集合,那么这些因子之间是可以相加或相减的。举个例子将两双球鞋相加在一起。注意看结果如何保留第一双潮鞋的宽踝环设计和品牌标志,同时保留第二双潮鞋的鞋底、整体轮廓和材质。

潮鞋图像隐空间算法
小贴士
嵌入是创建可重用值的绝佳工具,其固有的属性与人类理解物体的方式相似。它们可以免去持续维护目录和依据变化改变归类的工作,并且嵌入的隐因子能被广泛应用。利用嵌入,你可以找到集群来执行批量标注、计算推荐和搜索的最相邻近、缺失数据插补以及重用网络以热启动其他机器学习问题。
下一篇:通信设计,你是干什么的?

