服务热线:010-66095089/13521200337(微信)


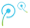

全国智慧农业“种子工程”案例征集活动号角吹响,2020我们一起出发!

【申报】AIOT ✖ 大农业生态峰会暨智慧农业“种子工程”案例征集

首届物联网与人工智能技术应用案例征集\/中国物联网与人工智能技术应用大会

关于征集发布前沿领域科技成果相关事宜


GMIC Beijing 2018 大会第一天,首个演讲者是 Facebook 首席 AI 科学家 Yann LeCun。他讲述了关于深度学习的最新研究成果,同时也描述了深度学习的未来,以及机器智能所要面临的的挑战。

▌监督学习无可替代
如今的 AI 系统都是使用的监督学习,所有的 AI 应用,不管是图像识别、声音识别还是人脸识别,或者机器翻译等等,这些都是监督学习的应用。训练监督学习模型需要向它展示各种例子,并告诉它正确答案,如果你想让机器学会将汽车和飞机区分开来,比如你给它展示一辆车的图像,它说这不是一辆车,然后你可以对参数进行调整,下次再向机器展示同一张图像的话,你就会得到接近正确的答案。
我们可以对机器进行端到端的训练,来完成特定的任务,feeding 原始的 inputs,就会自动给出 outputs。机器学习这个任务的过程是端到端的学习过程。通过这种方式机器,计算机能更好地了解这个世界。

比如卷积网络,实际上这个想法是可以回溯到上个世纪八十年代。它可识别图像,同时也有很多其他的应用,比如说可以用于语言处理、语言识别和其他很多的应用。我们知道对于神经网络是非常大的,只有在非常强大的计算机上才可以运用,需要有 GPU 加以辅助。

在深度学习变得比较普遍之前,我们首先要确保这样的一些系统可以用于这些情况,比如一个例子是我们在 2009 年、2010 年在纽约大学合作的一个实验,可以看到它可以识别马路上的建筑、天空以及路上的车和人等等,这个在当时并没有被称为最好的系统。再过几年之后,越来越多人相信深度学习是可以奏效的,可以发挥作用的。

在这里大家可以看到在网络当中使用的几个层,比如说有 100 层或者 180 层的一些人工神经网络,在 Facebook 当中我们就会广泛使用。这上面大家可以看到错误率是在不断下降的,有的时候表现的甚至要比人还要好。它的性能非常好,已经成为了一种标杆。
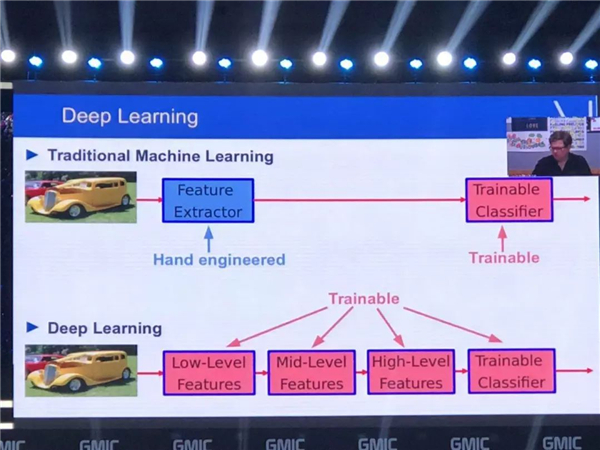
这是 Facebook 人工智能部门所做的研究,叫做 Mask R-CNN,可以看到它的结果,它可以标记这样的图像,就像我刚才给大家展示的例子,展示出非常好的性能。它不仅仅可以识别出每个人,同时它会为每个人加一个标记,所以可以很容易区分出是一个人还是一只狗。

在这里大家可以看到这个系统可以识别电脑、酒杯、人、桌子,也可以数出来到底有多少,而且也可以识别出道路、汽车。如果五年之前问系统这些问题的话,我们当时可能认为需要 10-20 年时间才能达到今天呈现的效果。

这也是 Facebook 所做的一些研究,叫做 Detectron。大家可以下载上面的代码,它可以探测 200 多种不同的类别,这也是 Facebook 在 AI 方面的一些研究,我们不仅仅发布了一些论文,同时连代码也都发布出来了,这样的话世界各地都可以更好的熟知这种技术。
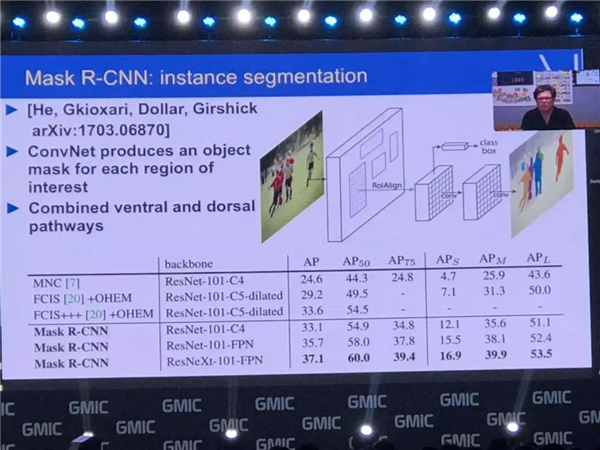
当然还包括其他很多项目,在 Facebook 我们利用 DensePose 这样的技术,预测人类的行为。我们现在有一个系统能够实时的运行,在一个单一的 GPU 上运行。它可以跟踪很多人的行为,生成视频,非常的准确,可以实时地生成一些相应的数据和信息,并且相应的代码也是可以用的,这些都是一些最新的应用。
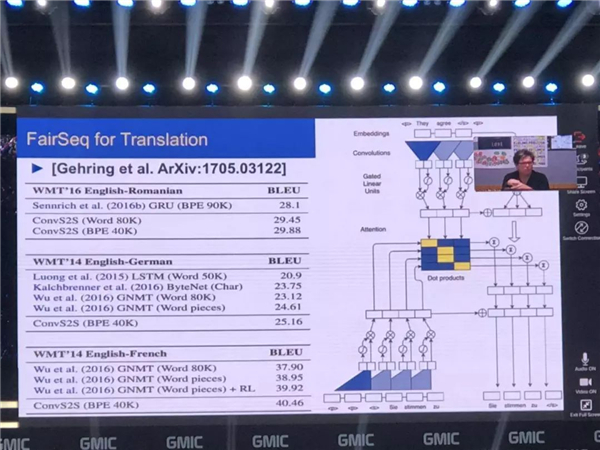
当然利用的这样的技术不仅仅可以进行识别图像,面部识别,也可以识别人的行动,也可以用来翻译,这是 Facebook 在加州所做的研究(FairSeq)。我们可以用这个系统进来行翻译的工作。
我觉得对于行业说进行这样的开发研究将是会是一个非常有用的过程,同时我们也希望自己所开发的技术能够引导整个社区,解决我们所感兴趣的问题。我们认为 AI 不仅仅会帮助我们解决问题,同时还会帮助我们解决很多人类自己无法解决的挑战,所以我们会与科学团队一起朝这方面努力。

这里是在过去的几年里,FAIR 所发布的一些开源项目,包括像深度学习网络,还有深度学习框架等等。

我刚才讲到每天都会有一些新的应用发布,而深度学习的广泛应用也进一步推动科学方面的研究。在接下来几年里深度学习会发生更大的革命。
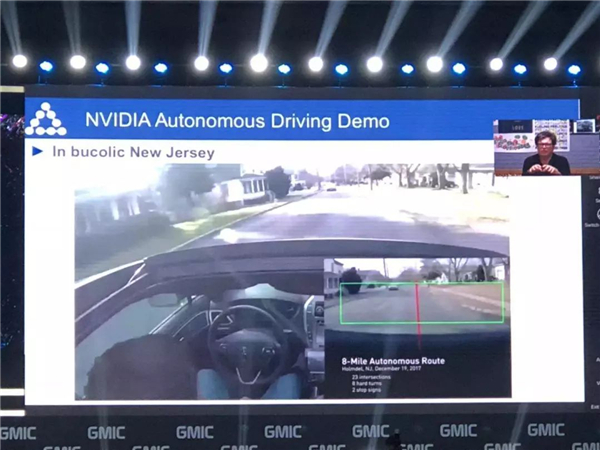
接下来为大家举一个例子,这段视频表现出来的是一种加速过程,它可以训练车去进行驾驶,而且可以调整车轮的方向。这样可以让车自己去进行驾驶,而不需要有人去进行校正。

▌可微分编程
接下来我们再来看一下可微分编程,这个编程可以用人工神经网络解释。
编者注:程序员不写代码,或者仅写出少量 high-level 的代码,但是提供大量输入数据 X 与对应运算结果 Y 的例子。神经网络根据提供的数据集,自动学出从输入数据X到最终运算结果 Y 的映射(既整个程序);或者结合程序员提供的 high-level 的代码,用神经网络作为中间函数,补全得到整个程序。
来源:知乎@殷鹏程
(https://www.zhihu.com/question/265173352/answer/291994649)
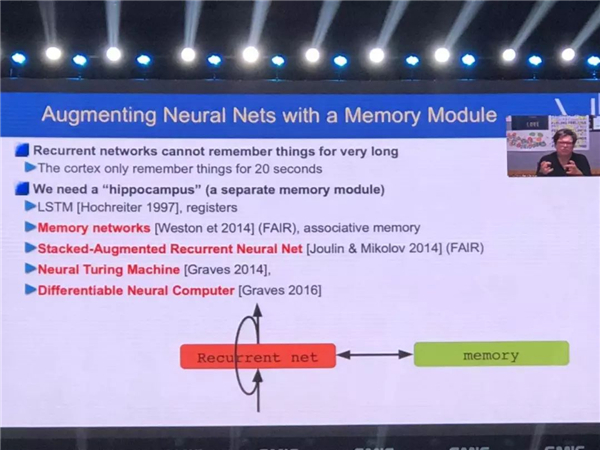
我们通过研究可以实现这样的一种编程,可以利用这样的系统或者培训系统,来完成某一个具体的任务。

这是几年前所开展的工作,是由 Facebook 和纽约大学一起合作做的项目。这个项目是训练模型,让它能够回答相关的问题。在自然语言处理过程中,也可以看到人工神经网络是动态的,在不断变化的。

这是另外一个例子,如果你要建立一个能够回答复杂问题的系统,比如说关于图像的复杂问题等。为了回答这个图片是不是有更多的立体形状,之后我们就会让系统来进行计算。比如说这里有多少是方形体,或者有多少颜色,最后告诉你具体的答案是什么。通过这么做我们可以建立起一个端到端的解答的途径,而且也允许你提出更多新的问题。根据你输入的数据不同,它会有所变化。

大家看到这里是我们最近开发所得到的一些深度学习最新的成就,之后我们来看一下关于 AI 有没有我们触及到的。

▌机器学习需要常识
对于新技术,我觉得可以进入到更多的领域,比如进行更多的影像分析。在一定程度上,我们觉得机器可能确实拥有一定的人工智能,但具体细节上,我们还需要进行更多探讨。
比如在机器学习方面,我们怎么做呢?在这儿可以看到有一些具体的图像,我们有些新的方法。在实际的生活当中其实这种方式不太成功,因为关于深度学习方面我们要进行深入的挖掘,因为对于机器本身它会有不同的解决方案,比如在实际生活中是不能够去实施的。

有时候让机器学习很长时间才能玩游戏。所以在核心功能方面,现在确实还没有触及到。但这些机器是能做到的,只是我们还没有挖掘出来。我们也可以对机器本身进行更深入的训练,比如我们要让系统进行成千上万次的训练之后,它们才能够进行学习。
有些学习它是与力学相关的,但是在实际的生活当中不可能实时进行,所以我们只能够进行模拟,但它也需要我们进行很多的尝试才能够让机器学到。

婴儿们是怎么学习的呢?比如就像右下角这幅图向他们所展示的,六个月以下的婴儿可能不太了解物理运动,可当他们满了八个月之后,他们已经知道自由落体这个动作了。
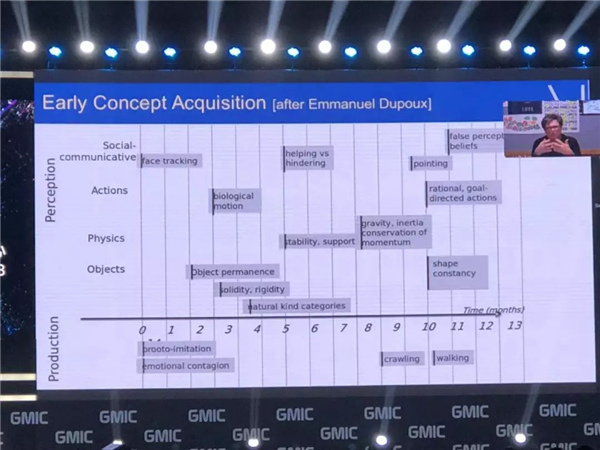
所以像右下角的这个小女孩非常了不起,我的一位朋友她给我们展示了婴儿怎么学会一些概念,而且他们也能够了解一些最基本的物理原理,这是他们在生活中最初学到的一些概念,这是凭借人们常识获得的,婴儿们所学会的是就是一些常识。
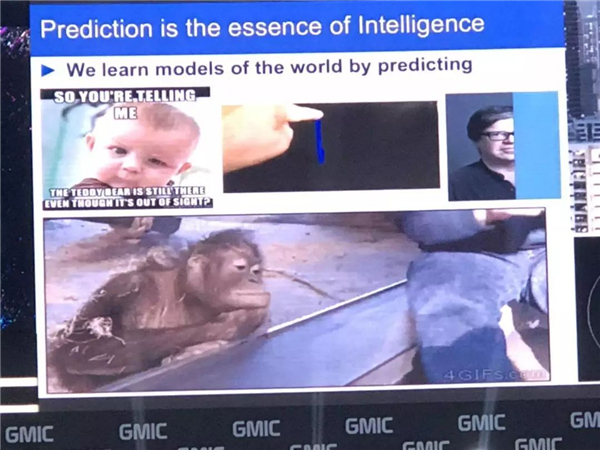
另外我们向动物展示这样的情景,比如大家看一下这个大猩猩,它们在幼年的时候由培训员给它们进行展示一些东西,所以大猩猩面对这样的魔术会笑出来,而人们会把这当做世界最初的原型。

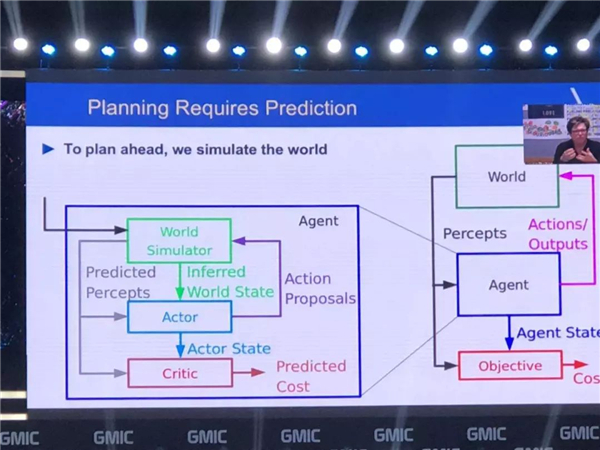
但我们希望机器能够建立一些样本,使得系统运行,最终机器就能进行一些预测,像人一样有效运行。我们有这样的监督或者学习就能够使得机器得到训练和规划,这是我们所需要建立的一个系统。

不管下次的变革出现在哪里,我觉得它们应该是自我监督或者无监督学习,而且在这样的变革当中也会出现一些常识性的学习。

我总结一下,这是我们最近做的一些非常有意义的事情,这是一些预测性的模型,来由机器进行规划,根据它们的尝试进行预测。
我们进行了对抗性训练,比如说我们可以训练机器来了解哪个分项是更可能的,或者在实际生活中会产生什么样的结果。对于发生的可能性它也会来做出预测,可能有的时候有的结果是虚假的,不是真实的。通过这么做我们就能够得到不同机器产生的结果,之后得到了很多的影像和图片。

我们的系统在进行训练之后,生成了一系列的人脸,大家看看这些名人的面孔,里面有一些是假的图像,是由机器生成的,但看起来是真实的。
我们将在下周会议上向大家展示最新的结果,得到的成果非常好。总之,我们希望把这个工具之后能够融入到我们的机器学习当中。

最后,我想做一下总结,我觉得监督学习是不能够被替代的,不管是无监督学习还是其他的学习方式都不能够替代它,这点已经引起了很多人的兴趣,我们也要进行更多尝试。还有一点我需要强调的是,我们要让机器能够推理,来看深深度学习能带给我们什么样的推理能力,同时也要了解在AI时代,机器的推理能力有多高,逻辑性有多强。
接下来我们也要来朝着可微分编程的智能学习的方向持续发展,这就需要进行做更多对抗性训练的研究。当然,还会出现更多的有关深度学习的变革,比如一些多渠道发展或者是复杂的架构,在这个领域也会出现更多的理论。

关于技术监督的趋势很显然是不断的弱化,甚至监督会消失,这就会导致出现一些新理论的产生,比如新语言,或者是一些新的并行文本,我相信之后应该有多维度的可能性。可能会出现一些新框架,包括了一些动态影像。我们会和微软,和亚马逊会进行更多合作,我们也会不断进行开源。
当然,现在我们的工作量很大,但是关于我们的移动工具和其他工具越来越流行了,Facebook 的用户他们每天能够推出大概 20 亿张不同的影像,所以我们希望能充分发挥这方面的能力,它可能是一种很强的驱动力。另外,我们也要不断强化硬件,以使用户需求能够得到专业化的处理。

